论文研究NEW
昨天
Pretrained dense visual features from Vision Transformers (ViTs) are powerful yet have been underutilized in robot learning. Modern robot policies either compress each observation into a single global…
共 214 条相关资讯 · 来自历史归档
Pretrained dense visual features from Vision Transformers (ViTs) are powerful yet have been underutilized in robot learning. Modern robot policies either compress each observation into a single global…
We propose one-step and two-step methods for policy learning with retrieval-augmented generation (RAG). We formulate RAG-based action selection under the potential outcome framework. In the two-step m…
PPO and the GRPO baseline studied here use clipped surrogate objectives whose favorable-direction saturation introduces an abrupt change in the scalar objective's derivative. We ask whether Output Res…
We propose Token-Level Off-Policy Labeling (TOPL), an off-policy training paradigm that reframes post-training as a token-level correctness prediction task. Our key intuition is that by training the m…
Large language model (LLM) post-training is essential for improving reasoning, adaptation, and alignment. Existing methods mainly follow two paradigms: reinforcement learning (RL) and on-policy distil…
IT之家 7 月 18 日消息,据路透社报道,反对 AI 数据中心快速扩张的民众计划于周六(7 月 18 日)在全美至少 125 个地点举行抗议活动。 此次抗议活动由一个名为“人类优先 (HumansFirst)”的民间组织牵头。抗议者将举行集会,反对“不受控的”数据中心扩张行为,以及“对我们自由不可容忍的侵犯”。 尽管遭到居民的强烈反对或缺乏监管审查,报道…
AI 点评 · AI扩张引发民间反弹,折射出科技发展与社区权益的深层矛盾。
Entropy control has become an effective tool in reinforcement learning (RL) of large language models (LLMs), helping balance exploration-exploitation trade-off during alignment process. Such RL paradi…
Transferring policies across domains poses a vital challenge in reinforcement learning, due to the dynamics mismatch between the source and target domains. In this paper, we consider the setting of on…

The company endorsed landmark AI transparency laws in California and New York last year, but its head of US state and local policy says they may already be outdated.
AI 点评 · Anthropic推动加速AI监管,显示行业巨头对现有法规可能滞后于技术发展的紧迫感。
Evidence synthesis is crucial for turning primary research into reliable knowledge for science, medicine, education, and policy. Yet, quantitative evidence synthesis remains largely manual and difficu…
AI 点评 · AI自动化元分析系统,极大提升科研效率,降低人工成本,推动循证决策发展。
We develop data-driven algorithms for maintaining $N$ independent identical machines under a \textit{block replacement policy}, in which each machine is replaced upon failure and all machines are join…
AI 点评 · 用数据驱动替代固定周期换件,显著降低维护成本,革新传统设备管理策略。
Large language models are increasingly trained as interactive agents for long-horizon tasks involving multi-turn interaction, tool use, and environment feedback. Outcome-based reinforcement learning (…
Reinforcement learning with verifiable rewards (RLVR) commonly uses entropy for advantage shaping. However, entropy cannot distinguish useful uncertainty from detrimental confusion, limiting its effec…
On-policy distillation is an alternative post-training method in reinforcement learning that alleviates the constraints imposed by reward models by providing token-level supervision from a teacher mod…
World Action Models (WAMs) improve robot policy learning by jointly modeling actions and future visual observations, using future scene evolution as dense supervision for physically grounded action ge…
On-policy distillation (OPD) has become a key paradigm in LLM post-training, yet its training dynamics remain poorly understood. We present a systematic study examining the role, pathologies, and regu…
Validating autonomous driving systems requires diverse, regulation-compliant test scenarios. In simulation-based testing, scenarios are defined as executable scripts. Yet automatically generating such…
Agentic language models must learn when to call tools, when to consume tool responses, and when to answer directly. This makes multi-teacher on-policy distillation a natural training strategy: one tea…
DeepMind CEO Demis Hassabis is proposing an AI "standards body" modeled after FINRA, to test frontier models and develop best practices for their release.
AI 点评 · 呼吁建立独立标准机构监管前沿AI,体现行业领袖对安全治理的紧迫感与务实路径。

IT之家 7 月 14 日消息,据科技媒体 The Verge 今天报道,谷歌 DeepMind 创始人兼 CEO 德米斯 · 哈萨比斯(Demis Hassabis)认为,美国政府应成立全球 AI 监督机构, 让人们能够在前沿 AI 模型发生险情时踩下“刹车” 。 哈萨比斯认为,美国应该主导这一倡议并制定全球标准。他认为这个设想中的机构可以参考美国金融业监…
凌晨三点,一家刚成立不久的AI创业公司,可能已经在同时服务旧金山的客户、采购首尔的技术服务,并与拉各斯的合作伙伴签下合同。这家公司甚至还没有招到第一名全职财务人员,业务却已经跨越多个市场、币种和监管辖区。 AI正在让这样的创业路径成为可能。过去需要市场、运营、客服等一整套全球化团队才能完成的工作,现在借助智能体就能承担相当一部分。新一代初创企业不必再按照“先…

In response to a public records request, HUD has withheld documents about DOGE’s use of AI—in part by citing a privilege that doesn’t exist.
今日热点导览 韩国法院禁止两名前三星员工就职于SK海力士 字节探索自动驾驶,Seed世界模型团队负责 巨力索具深夜澄清商业航天业务不实传闻,提醒投资风险 科技记者古尔曼:苹果将跳过M6 Pro/Max芯片全力押注AI导向的M7系列 美众议院本周将表决永久实行夏令时法案 TOP 3大新闻 海南将成中国首个禁售燃油车省份,届时车桩比保持2.5:1以下 近日,海南…
Structured pruning is a hardware-friendly way to compress LLMs, but it is mostly validated on multiple-choice recognition tasks, while the same compressed checkpoints can collapse on the free-form gen…
Explainability has emerged as a critical requirement for AI-based systems, particularly in safety-critical and regulated domains. Although prior research has proposed frameworks, patterns, and user-ce…
Post-training is essential for refining the domain-specific capabilities of large language models (LLMs), yet existing reward optimization and distribution matching methods tightly couple policy explo…

IT之家 7 月 11 日消息,近期有消息称,腾讯正考虑入股 AI 初创公司 Manus,计划成为该公司的最大股东。腾讯正与真格基金、红杉资本和 Manus 管理层磋商,计划按 20 亿美元收购这家 AI 公司。 据财闻今晚报道,接近交易的知情人士表示, 此次 股权变动 是在 监管主导之下 , 社会资本共同补齐此前 Meta 的投资,以便让 Meta 退出…
AI 点评 · 腾讯入股Manus或为监管主导下的资本重组,Meta退出值得关注。
Agentic retrieval-augmented generation (RAG) extends static RAG by allowing language models to iteratively reason, generate search queries, retrieve evidence, and predict answers. However, it remains…
Pre-demolition assessment, the regulated audit process at the heart of urban mining, is an information process in which AI support must serve qualified auditors who remain accountable for the decision…
AI 点评 · 知识图谱与可解释AI结合,让城市矿产审计更透明可信。
About two weeks after OpenAI's GPT-5.6 was caught up in regulatory drama - rolled out only to government-approved organizations during a "limited preview" period - the company has…
We propose OPSD-V, an on-policy self-distillation paradigm for post-training few-step autoregressive (AR) video diffusion models. Existing few-step AR video generators can produce long videos with low…

Today, we're announcing the Claude apps gateway for AWS, a self-hosted control plane that gives organizations a single point of control over access, cost, and policy for Claude Cod…
AI 点评 · 企业级AI部署新方案,统一管理Claude访问权限与成本,解决安全合规痛点。
Group Relative Policy Optimization (GRPO) stalls on a model's hardest problems: when no rollout in a group succeeds, the group-relative advantages vanish and the problem contributes no gradient, wasti…
Reinforcement learning with verifiable rewards (RLVR) is a powerful recipe for improving language-model reasoning, but it is expensive to repeat on every new strong model because the target model must…
鉴于ChatGPT、Claude和Gemini等大型语言模型对消费者财务决策的影响日益增加,英国金融监管机构被敦促考虑对这些模型进行监管。在英国金融市场行为监管局(FCA)委托进行、于周一发布的一份评估报告中,FCA执行董事米尔斯(Sheldon Mills)也强调,企业对少数几家技术供应商的依赖可能带来全系统范围的风险。(新浪财经)
AI 点评 · 监管关注金融领域AI依赖少数巨头,防范系统性风险与消费者保护成关键看点。
On-policy distillation (OPD) trains a student policy by matching a stronger teacher on the student's own trajectories, offering a promising framework for language agent training. However, its applicat…
Image guardrails are typically trained and evaluated under a fixed safety policy, implicitly treating safety as an intrinsic property of an image. Real deployments are different: the same image may be…
Reinforcement learning with verifiable rewards (RLVR) is a powerful recipe for improving language-model reasoning, but it is expensive to repeat on every new strong model because the target model must…
Occupancy ratios correct distribution shift in offline reinforcement learning and are central to off-policy evaluation. Existing primal-dual and minimax methods typically estimate these ratios by enfo…
Group Relative Policy Optimization (GRPO) is effective when the current policy already samples useful reasoning trajectories, but it stalls on hard prompts whose correct solution modes lie outside the…

FCA official makes case for greater powers for watchdog as millions use technology for personal finance decisions.
For robots to work reliably in commercial and industrial applications, can recent advances in agentic coding systems combine interpretable robot programming with the open-world adaptability of model-f…
Unified models for robot manipulation aim to equip one policy with both the semantic priors of pretrained VLMs and the physical dynamics learned through future prediction. In practice, existing design…
Group Relative Policy Optimization (GRPO) is effective when the current policy already samples useful reasoning trajectories, but it stalls on hard prompts whose correct solution modes lie outside the…
Big goals are hard to achieve all at once; breaking them into small steps is wiser. We present Trust Region Policy Distillation (TOP-D), which transforms the notoriously unstable, high-variance On-Pol…
Diffusion large language models (dLLMs) generate text by iteratively denoising a masked sequence, offering a parallel alternative to autoregressive models, but eliciting strong reasoning through post-…
Recent advances in multimodal foundation models and agent systems have driven GUI agents from single-platform task execution toward cross-platform interaction. However, building multi-platform GUI age…
Reinforcement learning (RL) for non-verifiable instruction following increasingly relies on LLM judges with prompt-specific rubrics as reward signals. While recent methods adapt these rubrics to the e…
今日热点导览 三部门:调整节能汽车、新能源汽车车船税优惠政策 三星传获Meta超10万亿韩元AI芯片代工订单 茉莉奶白小程序更换彩色Logo Meta打算出售富余算力引发科技股回落 英伟达前光互连技术高管Ashkan Seyedi加入艾迈斯欧司朗 TOP3大新闻 因存在植入后门风险,阿里内部全面禁用Claude Code 36氪从阿里内部人士处获悉,因近期C…
AI 点评 · 阿里禁用Claude Code凸显企业数据安全红线,AI工具合规性成焦点。
Visual policies learned from human videos, teleoperation, and robot demonstrations offer scalable motion priors, but often fail in contact-rich manipulation, where success significantly depends on loc…

IT之家 7 月 3 日消息,豆包今晚发布《豆包智能体功能下线通知》,称由于产品功能调整, 智能体功能将于 2026 年 7 月 15 日下线 。 《通知》显示,该功能下线后,用户仍可在一段时间内查看并自行保存智能体信息及历史对话数据。2026 年 10 月 15 日后,豆包将根据《隐私政策》对智能体相关数据进行处理, 后续将无法在豆包内查看或恢复 。如有重…
AI 点评 · 产品功能调整背后,需关注用户数据迁移与隐私政策变化对AI服务稳定性的影响。
On-policy self-distillation (OPSD) has emerged as a practical method for training large language models (LLMs) to reason, where a single model acts as both the teacher and the student with different l…
Autonomous agents are increasingly expected to improve executable policies through feedback, yet existing evaluations often collapse this process into a final score or confound it with open-ended soft…
Continual post-training enables foundation models to acquire new knowledge while preserving existing capabilities. Recent work suggests that on-policy learning can mitigate forgetting, with on-policy…
Vision-Language-Action (VLA) foundation models have recently achieved strong progress in embodied intelligence. To reduce policy-call frequency while preserving temporal coherence, most generative pol…
We present EVA-Client, an open-source framework for deployment, data collection, and evaluation of trained manipulation policies on real robots. Sitting between a policy server and the physical hardwa…
Evaluating embodied robot foundation models remains a critical bottleneck; unlike large language models efficiently assessed via digital benchmarks, robotic policies require slow, costly real-world ro…
Cloudflare is giving AI companies until September 15 to separate web crawlers used for search from those used for AI training and agents, or risk being blocked by default on many p…
AI 点评 · 云服务商首次明确要求AI训练爬虫付费,或重塑数据获取规则。
The Trump administration's erratic approach to AI policymaking has left companies across the industry with little clarity about what will govern future model releases.
Touch supplies the physical grounding needed to perceive intrinsic material properties, such as friction and compliance, that vision alone often cannot resolve. Recent efforts for equipping multimodal…
Reward design remains a central bottleneck for autonomous robot policy improvement, especially in long-horizon manipulation tasks where sparse success labels provide too little signal and binary prefe…
Policy-grounded document review requires determining whether a target document complies with organization-specific policies, guidelines, or playbooks. While large language models can assist with polic…
Metacognition is a critical component of intelligence that describes the ability to monitor and regulate one's own cognitive processes. Yet LLMs exhibit systemic deficiencies in key metacognitive facu…
Speculative decoding accelerates inference by using a lightweight draft model to generate candidate tokens in parallel, and are then verified by the target model, enabling lossless acceleration. Recen…
Conservative offline training is widely advocated as a safe foundation for subsequent online adaptation: if a policy stays close to well-supported behaviour, the argument goes, it is less likely to ex…
On-policy distillation (OPD) offers superior capacity transfer by supervising student-sampled trajectories with dense token-level signals. To furnish high-quality supervision sources and thereby eleva…
Open-source local policy, recovery, and audit layer for explicit Codex execution.
In real-world applications, guardrails are often expected to identify unsafe user-model interactions according to application-specific safety policies, rather than relying on predefined risk taxonomie…
Modern large language models (LLMs) rely on reinforcement learning during post-training to push specific capabilities, yet integrating multiple capabilities into one model remains hard. Existing metho…
On-policy distillation (OPD) offers superior capacity transfer by supervising student-sampled trajectories with dense token-level signals. To furnish high-quality supervision sources and thereby eleva…
LLM agents handle user requests on behalf of organizations through tool calls and must follow the company policies stated in their system prompts. Prior work approaches this as a safeguarding problem…
6月26日,北京人形机器人创新中心慧思开物平台的双大脑模型天鹕(Pelican-VL)和我悟(WoW)同步完成北京市网信办最新一批生成式人工智能服务备案。北京人形将正式启动慧思开物全系列模型Token服务,计划分阶段面向产业客户、科研机构、开发者全面开放API调用能力。(界面新闻)
AI 点评 · 具身智能迈入备案监管时代,标志人形机器人商业化落地加速。

IT之家 6 月 27 日消息,据央视新闻 6 月 25 日报道,市场监管总局正会同相关部门,加快智能体等前沿技术领域标准制定速度,动态完善适配产业发展的人工智能国家标准矩阵。 报道称,目前正在抓紧制定的国家标准,除智能体外,还有 具身智能、世界模型、本体模型 等前沿技术标准,算力基础设施、高质量数据集、仿真测试平台、深度学习编译器、开源模型平台等底座类标准…
AI 点评 · 政策加速标准制定,将推动智能体与具身智能产业规范化发展,抢占技术制高点。
Less than 24 hours after news broke that OpenAI would stagger its next model release at the request of the Trump administration, that model, GPT-5.6, is here. On Friday, the compan…
AI 点评 · 政商博弈下加速发布,凸显AI巨头在监管压力中的技术突围与市场策略。
In this post, you learn how Stripe built a production-grade AI agent system for financial compliance. We cover the technical architecture of Stripe’s ReAct agent framework and the…

IT之家 6 月 26 日消息,据《纽约时报》昨日援引三位内部人士消息,OpenAI 正考虑将 IPO(首次公开募股)推迟至明年进行。 此前曾有传闻称,OpenAI 已向美国监管机构秘密递交 IPO 申请,目标估值最高可达 1 万亿美元(IT之家注:现汇率约合 6.82 万亿元人民币)。但根据内部知情人士所述,目前 OpenAI 向顾问公司提出了两种方案:…
AI 点评 · 推迟IPO或为稳固万亿美元估值,反映其战略定力与市场博弈,值得关注。
Training and evaluating robot policies in the real world is costly and difficult to scale. We introduce SimFoundry, a modular and automated system for zero-shot real-to-sim scene construction from a v…
Outcome-based reinforcement learning provides a stable optimization backbone for language agents, but its sparse trajectory-level rewards provide little guidance on which intermediate decisions should…
Modern image generation demands a single model that unifies diverse capabilities, including text-to-image (T2I), local editing, and global editing. However, these capabilities are rarely naturally ali…
We present Qwen-Image-2.0-RL, a post-training pipeline that applies reinforcement learning from human feedback (RLHF) and on-policy distillation (OPD) to improve both the visual quality and instructio…
Most Vision-Language-Action (VLA) models build on a Vision-Language Model (VLM) backbone by attaching an action module and optimizing the full policy jointly. This design inherits strong visual and li…
On-policy self-distillation achieves strong pass@1 accuracy by using a single model as both teacher and student, with the teacher conditioned on a correct demonstration to provide dense token-level fe…
IT之家 6 月 24 日消息,据纽约时报消息,知情人士透露,美国政府正向 Meta 施压, 要求其主动提交人工智能模型以供审查 ,以便政府能够评估这些模型的功能与潜在漏洞。 IT之家从报道获悉,在目前美国主要的 AI 技术开发商中, Meta 是唯一一家尚未与政府达成自愿共享模型以供审查协议的公司 。目前 OpenAI、Anthropic、谷歌、xAI 和…
AI 点评 · 监管力破AI巨头技术壁垒,Meta若松口将成行业风向标,安全审查或成全球治理新标杆。
Fine-grained visual reasoning requires multimodal large language models (MLLMs) to identify task-relevant visual evidence and ground their reasoning in local image regions. Existing agentic methods ty…
Hello and welcome to Regulator, the newsletter for Verge subscribers chronicling the misadventures of their favorite tech overlords and Washington swamp creatures. ("Favorite" is,…
AI 点评 · 企业AI超级政治行动委员会重金投入地方选举,揭示科技巨头正深度介入政治权力布局。
大公司: 甲骨文上财年裁员约2.1万 甲骨文上财年裁员约2.1万,减员规模大于此前已知水平,其中包括因使用人工智能(AI)而被取消的岗位。甲骨文周一在年度财务监管申报文件中称:“我们在各项业务中采用和部署AI技术,已经导致并且未来可能继续导致员工人数减少。” 英伟达宣布Vera Rubin NVL4系统Q4起供货 6月22日,英伟达宣布推出Vera Rubi…

IT之家 6 月 23 日消息,根据 Anthropic 公司新版隐私政策,该公司可能会要求 Claude 用户上传政府签发的证件来验证其年龄和身份。 这家人工智能企业表示,推出该项举措,是为了给账号被标记为存在潜在欺诈行为的用户提供申诉渠道,而非直接封禁账号。与此同时,Anthropic 正试图缓和与特朗普政府之间的矛盾,双方围绕谁有权使用该公司 AI 工…
AI 点评 · AI安全与合规升级,平衡用户隐私与反欺诈需求,折射行业监管趋严趋势。
Generalist value models play a pivotal role in scaling robotic policy learning from large-scale, mixed-quality data. Mathematically, accurate value estimation demands deep temporal understanding, requ…
Jailbreak attacks reveal a persistent weakness in aligned Large Language Models: carefully crafted prompts can elicit policy-violating responses despite safety training. While most defenses operate at…
On-policy distillation (OPD) trains a student on its own rollouts guided by teacher feedback and is becoming increasingly important for large language model (LLM) post-training. Like reinforcement lea…
36氪获悉,中信建投研报称,市场短期呈现强劲反弹行情,但反弹完成后A股或将进入震荡期。继续看好AI算力作为本轮行情中长期核心主线的后续表现。陆家嘴金融论坛等国内政策红利有望继续推动双创板块上涨,预计创业板和科创板将继续保持强势。而估值高企和交易结构可能成为后续科技主线阶段性切换的主要原因。重点关注AI算力、工业金属、石化、机械、新能源等,逢低布局:银行、非银…
AI 点评 · AI算力获机构力挺,中长期主线地位明确,政策红利与板块轮动成焦点。
英特尔将为苹果代工芯片 库克称 iPhone 涨价不可避免 美国科技公司政策转向,限制员工 AI 成本 Modos 推出开源 13.3 寸彩色墨水屏 Manus 原投资人计划将其原价购回 CMF 已取消今年发布计划 看看就行的简讯 少数派的近期动态 你可能错过的好文章 查看全文
On-policy distillation (OPD) improves LLM reasoning by training a student model on its own generated outputs, but standard OPD treats all student-generated outputs (SGOs) equally regardless of their i…
Vision-language models (VLMs) are increasingly deployed in consumer, medical, financial, and enterprise applications. This broad deployment expands the safety surface: risks can arise from multimodal…
Vision-Language-Action (VLA) models provide a unified paradigm for robotic manipulation, yet their real-world deployment is often bottlenecked by execution efficiency. While existing efforts predomina…
挪威首相斯特勒6月19日表示,为防止对学习产生负面影响,挪威将禁止小学生使用生成式人工智能工具,同时限制人工智能工具在高年级学生教育中的使用。根据挪威政府公布的方案,6到13岁的小学生原则上不得使用人工智能工具;14到16岁的初中生可在教师的严密监管下谨慎使用此类工具。17到19岁的高中生应学习如何恰当地使用人工智能工具,以便为后续的高等教育和未来的职场环境…
AI 点评 · 全球首个国家层面禁止小学生用AI,反映教育界对技术冲击的深层忧虑。
IT之家 6 月 19 日消息,据美联社报道,当地时间周四,美国联邦能源监管委员会下令,要求 6 家区域电网运营商加快 大型用电设施接入美国老化且效率低下的输电系统 。委员会表示,AI 数据中心耗电量巨大,用电需求又在迅速增长,美国必须加快并网流程。 美国能源部长克里斯 · 赖特此前敦促委员会采取行动,希望增强美国在 AI 领域与中国竞争的能力。 科技公司和…
AI 点评 · AI电力需求倒逼电网改革,揭示AI发展对基础设施的深层依赖。
Latent action pretraining learns representations of visual change from pairs of observations, but existing methods typically encode each transition as a single unstructured representation that entangl…
OpenAI is bulking up before its IPO, landing Transformer co-inventor Noam Shazeer from Google DeepMind and former Trump AI policy official Dean Ball in the same week.
AI 点评 · OpenAI上市前挖角Transformer发明者与政策要员,人才储备信号强烈。
Prior work has shown that in-context demonstrations can jailbreak language models, but it remains unclear how models interpret different types of compliance demonstrations. We study this by mixing ben…
Policy-adherent tool-calling agents in customer-service domains must maintain task states across turns while calling tools and obeying domain policies. Task states consist of relevant facts, identifie…
Achieving dexterous robotic manipulation in the real world heavily relies on human supervision and algorithm engineering, which becomes a central bottleneck in the pursuit of general physical intellig…
MLLM-based mobile GUI agents have made substantial progress in UI understanding and action execution, but adapting them to real target apps remains costly because mobile apps are numerous, frequently…
Hello and welcome to Regulator, an email for Verge subscribers about technology, politics, and what happens when science crashes headlong into self-interest. Not a subscriber? Sign…
大公司: 监管约谈山姆后,沃尔玛中国多位高管变动 36氪了解到,山姆会员商店中国 CMO(首席采购官)张青已于近日提交辞呈。此外,据36氪独家了解,沃尔玛中国本次人事变动还包括:Tony Paladinetti,现任沃尔玛国际部战略副总裁,将加入沃尔玛中国,担任沃尔玛中国战略副总裁,直接向朱晓静汇报。内部邮件称,Tony将在完成工作签证流程后于2026年8月…
On-policy self-distillation (OPSD) trains a model on its own rollouts and uses a frozen copy to provide dense token-level targets conditioned on a reference target. This works well for LLM reasoning,…
Reinforcement Learning with Verifiable Rewards algorithms like GRPO have emerged as the dominant post-training paradigm for complex reasoning in LLMs, yet commonly suffer from policy entropy collapse…
Current agentic robot systems can write executable Code-as-Policy programs, observe feedback, and revise behavior across multiple attempts, but they remain largely task-driven: reusable skills are acq…
Robots deployed in the real world should learn from their experience and improve over time. This requires a mechanism of practicing and learning from feedback. In this paper, we propose VERITAS, a gen…
With sophisticated cyber-attacks becoming increasingly prevalent, modern networks require intelligent autonomous cyber-defense agents trained via Reinforcement Learning (RL). These agents employ neuro…
今日热点导览 国内品牌金饰价格普涨 小红书公布世界杯开赛数据 阿里巴巴达摩院退出旗下科技公司 罗马仕接连变更法定代表人 遇见小面创始人向“渝见小面”致歉 TOP3大新闻 针对多发食品安全问题,市场监管总局约谈山姆总部 记者15日了解到,针对一段时期以来监管发现和媒体曝光的山姆线下门店及线上网店多发的食品安全问题,近日,市场监管总局依法对沃尔玛(中国)投资有限…
AI 点评 · 山姆被约谈、智谱股价飙升、美伊达成协议,三件大事同日凸显监管、科技与地缘政治的联动影响。
On-policy self-distillation (OPSD) has proven effective for post-training large language models (LLMs), yet its application to diffusion LLMs (dLLMs) remains unexplored. Existing OPSD methods are inhe…
Knowledge distillation transfers a teacher's competence to a small student but is brittle in the small-student regime: forcing the student to imitate logits from a much larger teacher concentrates it…
Memory has become a standard substrate for self-evolving agents, yet retaining experience is not the same as learning how to evolve through it. Existing memory agents can store trajectories, retrieve…
Graphical user interface (GUI) grounding requires vision-language models (VLMs) to identify small target elements in high-resolution screenshots and predict precise screen coordinates. On-policy self-…
Heterogeneous Treatment Effect (HTE) identification is crucial to explain the impact of an intervention and optimize our policies accordingly. Existing approaches trade expressivity for interpretabili…
For months, Big Tech's Washington lobbyists have chased after the holy grail of pro-AI legislation: preemption. This would be a comprehensive federal law, passed in Congress and si…
As LLMs advance, post-training reinforcement learning (RL) increasingly relies on multi-dimensional rewards to cultivate comprehensive capabilities. This shift demands new algorithms capable of optimi…
Generalist robot policies must follow user instructions while reasoning about how objects, cameras, and robot actions interact in the 3D physical world. Recent vision-language-action models (VLAs) and…
Reinforcement learning with verifiable rewards (RLVR) improves language-model reasoning, but GRPO-style optimization remains prone to collapse. We analyse this instability through token-level gradient…
Extending a vision-language-action (VLA) policy to a new task typically requires task-specific teleoperated demonstrations and per-task fine-tuning, making adaptation costly in both data collection an…

An expert in behavioral science and transportation, Zhao combines these studies with AI and public policy to address some of the most urgent challenges facing cities.
AI 点评 · 行为科学与交通专家赵华将AI融入城市政策,为解决城市紧迫挑战带来新视角。
Large reasoning models typically follow a read-then-think paradigm: they observe the complete input, reason over a static context, and then produce the answer. Yet many real-world scenarios are inhere…
When applying Group Relative Policy Optimization (GRPO) for GUI Grounding, rollouts are sampled from a single screenshot view; groups often become either all failures on difficult instances or all suc…
On-policy distillation (\textsc{OPD}) has recently become a prominent post-training recipe as it combines two desirable ingredients: on-policy student trajectories and dense teacher supervision, yet h…
Anthropic Walks Back Policy That Could Have ‘Sabotaged’ AI Researchers Using Claude Big scoop for Maxwell Zeff at Wired: “We’re changing Fable 5’s safeguards for frontier LLM devel…
https://archive.ph/yxYhU https://web.archive.org/web/20260611033414/https://www.wired...
36氪获悉,中信建投研报指出,6月行业配置建议采用“杠铃结构”:一端保留AI、半导体和出口制造等高景气底仓,另一端配置高股息、现金流稳定资产控制组合波动,中间用周期涨价、新能源修复和政策订单主题做弹性仓位。5月市场主线高度集中在通信、电子、AI硬件链,说明资金仍围绕产业景气和业绩兑现定价,但AI链短期涨幅较大、交易拥挤度上升,6月不宜继续提升AI总仓位,内部…
AI 点评 · 杠铃策略兼顾进攻与防御,精准捕捉6月市场结构性机会。
Latent chain-of-thought compresses reasoning by replacing visible reasoning traces with continuous hidden-state recurrence, but existing formulations are difficult to optimize with standard on-policy…
The potential impacts of world models (WMs, i.e., learned simulators) on robotics are far-reaching -- policy evaluation, policy improvement, and test-time planning -- all with limited real-world inter…
On-policy distillation (OPD) has recently become a prominent post-training recipe as it combines two desirable ingredients: on-policy student trajectories and dense teacher supervision, yet how this h…
AI 点评 · 关注点在于政策如何应对AI指数级增长带来的安全与治理挑战。
Contact-rich manipulation requires force sensitivity, but many robot arms lack dedicated force sensors due to their high cost. We present Neural External Torque Estimation (NEXT), a data-driven method…
Recent advances in agentic Reinforcement Learning (RL) have substantially improved the multi-turn tool-use capabilities of large language model agents. However, most existing methods assign credit ove…
Human-in-the-loop reinforcement learning (HiL-RL) has emerged as an effective paradigm for real-world robotic manipulation, enabling online policy improvement with human guidance. However, current HiL…
Hello and welcome to Regulator, a newsletter for Verge subscribers about tech politics, tech influence, and tech shenanigans in Washington, DC. (If you're not a subscriber, you can…
AI 点评 · AI监管正让立场迥异的群体被迫合作,折射出政策博弈的复杂与紧迫。
We propose Ambient Diffusion Policy, a simple and principled method for imitation learning from suboptimal data in robotics. High-quality, task-specific robot data is expensive and time-consuming to c…
Recent advances in agentic Reinforcement Learning (RL) have substantially improved the multi-turn tool-use capabilities of large language model agents. However, most existing methods assign credit ove…
Understanding and predicting how social beliefs evolve in response to events -- from policy changes to scientific breakthroughs -- remains a fundamental challenge in social science. Given LLMs' common…
Reinforcement learning with verifiable rewards (RLVR) is a promising approach for enhancing reasoning and agentic behavior in large language models. However, rollout-intensive policy optimization is o…
Explore our ambitious, people-first industrial policy ideas for the AI era—focused on expanding opportunity, sharing prosperity, and building resilient institutions as advanced int…
Given how badly burned anyone who took Apple's 2024 WWDC Apple Intelligence announcements at face value was, I'm holding to a strict "I'll believe it when I see it" policy for ever…
AI 点评 · 苹果Siri AI若在WWDC 2026兑现承诺,将扭转此前画饼争议,值得关注其实际落地。
36氪获悉,中信建投研报指出,本周股票成交额环比出现回落,但继续维持高位,市场交投情绪仍在较高水平。当前保险板块估值具有较高配置价值,当前股价过度反映较高基数带来的潜在业绩增速压力,资产端回暖有望带动二季度利润增速和股价修复。港股非银板块在低估值特征与盈利改善预期共振下中长期配置价值凸显。监管逻辑趋稳、促消费导向明确、AI技术提效的背景下,消费金融行业处于政…
AI 点评 · 市场活跃叠加低估值,非银及消费金融板块存修复与配置机遇。
Recent work has demonstrated that online reinforcement learning (RL) can substantially improve the quality and alignment of flow matching models for image and video generation. Methods such as Flow-GR…
The success of Large Language Models in mathematical reasoning relies heavily on the generation of diverse and valid solution paths during the rollout phase. However, current rollout techniques face a…
Training reinforcement learning (RL) policies from scratch is costly: it requires careful reward and environment design, extensive tuning, and substantial computation. Yet many control problems alread…
AI 点评 · 无需从头训练策略,巧妙迁移智能体,大幅降低强化学习成本。
Reinforcement learning (RL) has become a key component of post-training large language models (LLMs). In practice, LLM RL is often off-policy because of training-inference mismatch and policy stalenes…
AI 点评 · 反思大模型强化学习中的散度正则化,揭示当前方法缺陷,为提升训练效率提供新视角。
World-action models have emerged as a promising paradigm for robot manipulation, jointly modeling visual scene dynamics and actions to inject physical priors into policy learning. However, existing wo…
Reinforcement learning (RL) has become a key component of post-training large language models (LLMs). In practice, LLM RL is often off-policy because of training-inference mismatch and policy stalenes…
Visual reasoning requires integrating evidence distributed across regions, attributes, and relations, making single-chain reasoning prone to early perceptual commitment and hallucination. We propose V…
On-policy distillation (OPD) trains a student on its own trajectories with dense per-token supervision from a stronger teacher, and often outperforms off-policy distillation and standard reinforcement…
On-policy distillation (OPD) has become a central post-training tool for large language models (LLMs), providing dense per-token teacher supervision along the student's own rollouts. In this work, we…
Krishnan is reportedly starting a new institution to continue shaping Trump's AI policy.
AI 点评 · 白宫AI顾问离职创办新机构,显示特朗普政府AI政策走向独立智库化。
World Action Models (WAMs) extend robot policy learning by incorporating future prediction as an additional training objective, encouraging the policy to encode task-relevant temporal structure in its…
加拿大政府4日正式公布名为“全民人工智能”(AI for All)的国家人工智能新战略。该战略计划投入数十亿加元公共资金,通过设立技术增长基金、扩大主权算力基础设施以及加强法律监管等核心举措,加快构建本土人工智能产业体系,全面推动技术普及与主权安全。新战略的核心举措之一是设立规模达5亿加元(约合3.6亿美元)的“加拿大技术增长基金”(Canadian Tec…
On-policy distillation (OPD) is increasingly used to improve large language model reasoning, but its training dynamics remain poorly understood. We characterize the trajectory of OPD updates in parame…
Vision-Language-Action (VLA) models are emerging as a promising paradigm for robotic manipulation, enabling general-purpose policies trained from large corpora of demonstrations and action labels. How…
Agentic reinforcement learning (RL) is emerging as a critical post-training paradigm for improving LLM agent capabilities. Existing RL algorithms for LLMs largely follow the token-centric paradigm as…
Recent advancements in reasoning language models have been driven by Reinforcement Learning (RL) fine-tuning. Most often, these rely on the Group Relative Policy Optimization (GRPO) algorithm or modif…
As autonomous LLM agents increasingly hold real credentials and operate infrastructure without a human in the loop, operators have no standard way to tell an agent that a resource is off-limits. Acces…
Autonomous driving requires reasoning about how ego actions shape the evolution of the surrounding world. However, most end-to-end methods rely on direct state-to-action mappings, capturing correlatio…
On-policy distillation (OPD) supervises the student only in output space by matching next-token probabilities. This output-only paradigm has two limits: (1) sampling variance from Monte Carlo KL estim…
We study the transformation of autoregressive models (ARLMs) into diffusion language models (DLMs). Rather than pretraining from scratch, prior work replaces the causal attention in ARLMs with bidirec…
Generalist robot intelligence is often framed as a policy-scaling problem: collect more robot demonstrations, train larger Vision-Language-Action (VLA) models, and expect broader generalisation. In th…
U.K. regulators are requiring Google offer a tool allowing website publishers to opt-out of generative AI search features. The option will be tested in the U.K. then rolled out glo…
OpenAI outlines its public policy agenda for AI, including safety, youth protection, workforce transition, and global standards to ensure AI benefits society.
Online publishers are getting more control over whether their websites appear in Google's AI Search features, thanks to a UK regulatory ruling. The new conduct rule imposed by the…
IT之家 6 月 3 日消息,据财经杂志报道,腾讯人士表示,目前无法确定微信 AI 智能体何时推出,其上线时间很大程度上取决于监管方对智能体的审批进度,微信 14 亿的用户体量,合规流程可能比其他产品更加严格。关于微信智能体,腾讯相关负责人表示暂无回应。 IT之家注意到,此前英国《金融时报》报道称,微信将推出一款 AI(人工智能)智能体,计划最快将于本月启动…
AI 点评 · 监管审批成关键变量,14亿用户规模下的合规挑战值得关注。
昨日,媒体报道称,微信将推出一款AI(人工智能)智能体,计划最快将于本月启动公开上线前所需的合规审批流程。腾讯人士表示,目前无法确定微信AI智能体何时推出,其上线时间很大程度上取决于监管方对智能体的审批进度,微信14亿的用户体量,合规流程可能比其他产品更加严格。关于微信智能体,腾讯相关负责人表示暂无回应。(财经)
AI 点评 · 微信14亿用户体量下,AI智能体合规审批进度成焦点,决定产品上线时间。
IT之家 6 月 3 日消息,美国总统唐纳德・特朗普于当地时间周二签署了一项行政令,推出人工智能企业自愿合作机制:AI 公司在前沿大模型正式发布前,可向美国联邦政府提交模型,以此“推动安全创新、强化关键基础设施网络安全防护”。 该行政令提出,美国人工智能产业能够蓬勃发展,部分原因在于“美方拒绝依靠繁重冗余的监管扼杀技术创新”,但同时新规也承认,新一代人工智能…
AI 点评 · 行政令体现美国平衡AI创新与安全的新思路,自愿评估机制值得关注。
Rubric-based reinforcement learning (RL) uses an LLM-as-a-Judge (LaaJ) to score model outputs according to rubrics as rewards. However, policy models may exploit latent biases in the judge, leading to…
The specification lets developer, compliance, and security teams define their own policies for agents to follow in portable policy files.
AI 点评 · 微软推出便携式策略文件,让开发者自主定义AI代理行为规范,提升安全可控性。
Classical reinforcement learning (RL) typically seeks a deterministic policy that maximizes the expected sum of a scalar reward. Yet, modern applications such as language model fine-tuning or scientif…
We implement simultaneous translation capability with the offline direct speech-to-text translation model Canary, using the state-of-the-art policy AlignAtt, and submit it to IWSLT 2026 Simultaneous S…
Self-distilled policy optimization (SDPO) has become a popular paradigm for LLM post-training, where a model learns from its own predictions conditioned on privileged information. SDPO, however, is se…
A new AI compliance service sits between AI models and end users to flag and replace any messages that might present a compliance problem.
AI 点评 · 融资千万美元,在AI输出端拦截违规内容,开辟模型安全新赛道。

IT之家 6 月 2 日消息,据路透社昨天报道,欧盟计划对高度敏感的政府云项目招标提出新标准,将微软、亚马逊和谷歌等美国大型科技公司排除在外。 IT之家援引路透社,本提案属于欧盟委员会《云与人工智能发展法案》的一部分,预计将在周三正式公布。 旨在进一步减少美国企业依赖 , 并推动欧洲本土产业发展 。 同时,欧盟不断在银行、能源和医疗等敏感领域实施“数字主权”…
AI 点评 · 欧盟加速“数字主权”战略,限制美企参与云招标,将重塑全球科技竞争格局。
As autonomous vehicle capabilities advance, the safe evaluation of driving policies in long-tail scenarios remains a critical bottleneck. In closed-loop simulation, the driving policy model actively i…
Reinforcement learning (RL) has become a dominant post-training paradigm, enabling large language models (LLMs) to learn from rewards. We observe that societal regulations are structurally similar to…
We identify a new dimension for enhancing rollout diversity in Group Relative Policy Optimization (GRPO) for LLMs. While GRPO relies on diverse rollouts, prevailing strategies primarily increase diver…
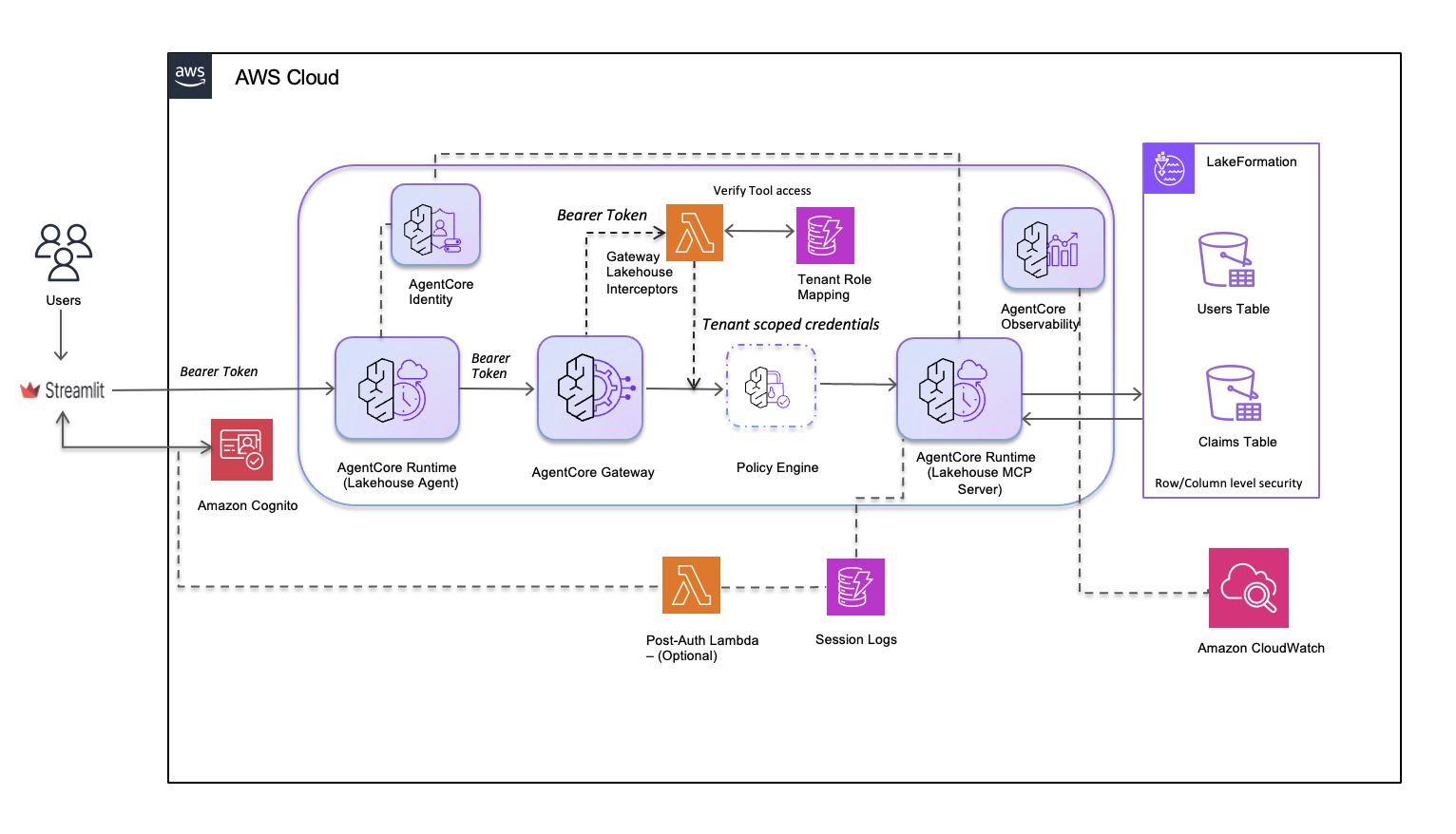
In this post, we use a lakehouse data agent to demonstrate how you can use Policy for deterministic access control and Lambda interceptors for dynamic validation. We then show how…
AI 点评 · 亚马逊Bedrock新功能实现AI代理安全管控,结合策略与动态验证,为行业提供可落地的防护方案。
Aligning Large Language Models (LLMs) with human values often degrades their general capabilities, termed the alignment tax. Existing methods mitigate this by balancing dual objectives, which heavily…
AI 点评 · 用局部策略蒸馏降低对齐成本,在保持安全性的同时避免通用能力下降,为高效安全对齐提供了新思路。
Our approach to AI policy and political advocacy, transparency, support for thoughtful regulation and AI safety, and that no outside political group speaks on the company’s behalf.
AI 点评 · OpenAI公开AI政策立场,强调透明度与安全监管,体现科技巨头在AI治理中的责任与影响力。
LLM agents are increasingly expected to operate across heterogeneous task regimes that require distinct execution paradigms. This challenges fixed agent systems and motivates system-level meta-adaptat…
Reinforcement learning (RL) improves large language model (LLM) agents by teaching them which actions lead to high rewards, but provides little supervision on what those actions do to the environment.…
On-Policy distillation (OPD) in large language models is shifting from full-trace KL supervision toward more selective training paradigms. Recent OPD methods increasingly focus on selecting which traj…
36氪获悉,华金证券发布研报称,复盘历史,影响6月A股市场走势的核心因素是政策和外部事件、基本面和流动性。今年6月A股可能延续震荡偏强趋势,受世界杯等因素影响有限。行业配置上,6月科技主线可能不变,建议继续逢低配置:一是政策和产业趋势向上的电子(半导体、AI硬件)、通信(AI硬件)、电新(AI电力、锂电)、军工(商业航天)、传媒(AI应用、游戏)、计算机(A…
AI 点评 · 科技主线延续性与政策事件共振,震荡市中结构性机会值得关注。
On-Policy Distillation (OPD) is a fundamental technique for efficient post-training of large language models (LLMs), with broad applications in agent learning, multi-task enhancement, and model compre…
Pope Leo XIV’s new encyclical on artificial intelligence includes a statement that warrants serious attention from technologists and policymakers: “Technology is never neutral.” Ma…
AI 点评 · 教皇通谕点破技术非中立本质,为人类应对AI时代提供伦理锚点。
Pope Leo XIV’s new encyclical on artificial intelligence includes a statement that warrants serious attention from technologists and policymakers: “Technology is never neutral.” Ma…
AI 点评 · 教皇通谕点破技术非中性,为AI伦理提供了超越功利主义的道德框架,值得科技与政策界深思。
Building strong reward models (RMs) for language model alignment is bottlenecked by the cost and difficulty of acquiring diverse and reliable preference data from human annotation or judge models. It…
AI 点评 · 用模型自身生成数据改进奖励模型,突破人工标注瓶颈,是RLHF的高效自监督路径。
Group-advantage-based reinforcement learning methods, such as GRPO and DAPO, have demonstrated strong performance across diverse domains, including mathematical reasoning and text-to-image generation.…
On-policy distillation (OPD) trains a student on prefixes sampled from its own policy while matching a stronger teacher. This addresses the prefix mismatch of offline distillation, but early student r…
Video world models (WMs) have shown promise for policy evaluation and improvement by imagining realistic future observations conditioned on ego-robot actions. While WMs can model distributions over fu…
AI 点评 · 用压力测试场景驱动视频世界模型,提升机器人策略评估的鲁棒性和改进效果。

Here’s why Anthropic and OpenAI are on board with Illinois safety testing.
AI 点评 · 伊利诺伊州AI新法获OpenAI支持,特朗普监管影响力减弱,行业安全标准或迎转折。
Here’s why Anthropic and OpenAI are on board with Illinois safety testing.
AI 点评 · 伊利诺伊州新法削弱联邦对AI监管主导权,获Anthropic和OpenAI支持,凸显行业对安全测试的
AI 点评 · Zig 明确拒绝AI并独立发展,揭示编程语言社区对技术自主性的新思考。
Explore OpenAI’s Frontier Governance Framework and how our AI safety, security, and risk practices align with emerging EU and California regulations.
AI 点评 · 首次披露AI安全与欧美监管对齐的具体实践,为行业合规提供参考。
Explore OpenAI’s Frontier Governance Framework and how our AI safety, security, and risk practices align with emerging EU and California regulations.
AI 点评 · 前沿治理框架首次将AI安全实践与欧盟、加州法规对标,为行业合规提供范本。
We study two-level autoresearch for cooperation: an outer-loop AI agent autonomously redesigns the inner-loop pipeline of an LLM policy-synthesis system for multi-agent Sequential Social Dilemmas (SSD…
AI 点评 · 自动探索合作策略的AI管道设计,为多智能体序贯社会困境提供创新解法。
While GUI agents have advanced rapidly, they often lack the robustness to recover from their own errors, hindering real-world deployment. To bridge this gap at both the evaluation and data levels, we…
AI 点评 · 为GUI智能体提供自我纠错能力评估基准与轨迹合成方法,填补了实际部署中的关键空白。
Reinforcement learning (RL) can be used to improve the policy (denoiser) of diffusion large language models (dLLMs), while being hindered by the intractability of the policy likelihood. A dominant and…
Speculative decoding accelerates large language model inference by pairing a target model with a lightweight draft model whose proposed tokens are verified in parallel. A common way to build draft mod…
AI 点评 · 通过在线策略蒸馏提升推测解码效率,为加速大模型推理提供了更优训练方案。
When a large language model under reinforcement learning commits a wrong reasoning step early in a trajectory, standard algorithms force it to keep generating until the maximum horizon, spending compu…
AI 点评 · 用早停机制提升强化学习训练大模型效率,大幅减少无效计算资源浪费。
Memory-augmented LLM agents tackle complex long-horizon tasks by recursively summarizing interaction trajectories into compact memory. However, existing approaches typically train these memory policie…
AI 点评 · ripgrep集成AI搜索,或成开发者效率利器。
On-policy distillation (OPD) trains a student on its own rollouts with token-level teacher supervision. Recent selective OPD methods exploit the non-uniformity of OPD signals by prioritizing high-entr…
Off-policy reinforcement learning of pretrained flow policies remains challenging due to the instability of optimization arising from the multi-step sampling process. Recently, Q-learning with Adjoint…
Customized image editing aims to equip pre-trained diffusion models with specific visual effects using limited paired data, typically via Low-Rank Adaptation (LoRA). As the number of desired effects g…
AI 点评 · 多教师在线蒸馏技术,让一个LoRA模型整合50种图像特效,显著降低部署成本。
Reinforcement learning with verifiable rewards (RLVR) has become a core technique for post-training of Large Language Models (LLMs). While policy optimization is driven by all sampled tokens under a g…
AI 点评 · 时间调度让强化学习从空间维度扩展到时间维度,为提升推理效率开辟新思路。
Multi-agent LLM workflows route inference through specialized roles to lift end-task accuracy, but jointly training those roles with reinforcement learning is unstable in ways that are poorly understo…
AI 点评 · 多智能体强化学习提升大模型协作效率的关键在于理解分工规模与策略共享的权衡。
Runtime security monitoring and control for AI agents. Catches malicious tool use, prompt injection, and policy drift in real time, before the agent acts.
Runtime security monitoring and control for AI agents. Catches malicious tool use, prompt injection, and policy drift in real time, before the agent acts.